Успех
или неудача веб-сайтов зависят от небольшого алгоритма — PageRank от
Google. В этой статье мы расскажем, как он функционирует.
Начнем
с прописных истин: Интернет огромен, а веб-страницы, наоборот, малы.
Многие из них предлагают похожий контент. При этом отдельному сайту
очень трудно подняться над этой массой. Пользователь сможет найти его
только в том случае, если запустит поиск Google и страница появится в
самом верху списка. Правила Интернета отличаются жесткостью и
напоминают о дарвиновской борьбе за выживание — это правила Google.
Однако если существуют сотни похожих страниц, то какая из них окажется
наверху, а какая будет загнана в конец списка? Ответ на этот вопрос
основатели Google Ларри Пейдж и Сергей Брин заложили в формулу
алгоритма PageRank. Тот, кто использует его, может сделать свое
присутствие в Интернете заметным. Тот, кто пренебрегает им, будет
наказан. Однако как же работает PageRank, и в каком случае веб-страница
попадает в верхнюю часть списка?
PageRank: как работает формула
PageRank возник из простого и гени-ального логического рассуждения. D
Для каждой веб-страницы найдется определенное количество страниц,
которые дают на нес гиперссылку. В Каждая из этих веб-страниц, в свою
очередь, тоже имеет PageRank. В Ссылка со страницы В на страницу А, как
при голосовании, может считаться одним голосом, отданным В за А. D
PageRank страницы В придает голосу, отданному за А, дополнительный вес.
Следовательно, чем выше PageRank страницы В, тем лучше. В В качестве
дальнейшего фактора рассматривается общее число ссылок, которые
находятся на странице В. Чем меньше число ссылок на странице В, тем
лучше это для PageRank страницы А.
Важно следующее: PageRank
рассчитывается не для какого-то веб-продукта, а каждой отдельной
страницы. Поэтому может случиться так, что определенный документ на
веб-сервере будет иметь более высокий PageRank, чем домашняя страница,
к которой он принадлежит. В виде формулы вся игра вокруг PageRank
выглядит следующим образом:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
Это читается так: PageRank страницы А складывается из PageRank страниц
Т1...Тп, разделенных соответственно на количество ссылок на этих
страницах. При этом следует еще учесть коэффициент затухания.
Принцип PageRank легко объяснить, если предположить, что весь Интернет
состоит всего из четырех страниц. Итак, даны страницы А, В, С и D.
Каждая имеет исходный вес PageRank, равный 1. Значения, взятые вместе,
соответствуют всей условной сети из четырех страниц. Для первого
примера будем исходить из того, что каждая из страниц В, С и D
демонстрирует одну ссылку на страницу А и помимо этого никаких других
ссылок нет. Если пока пренебречь некоторыми другими факторами,
влияющими на PageRank, получается такая формула: PR(A)= 1/1 + 1/1 + 1/1
Она дает значение PageRank для А, которое равно 3.
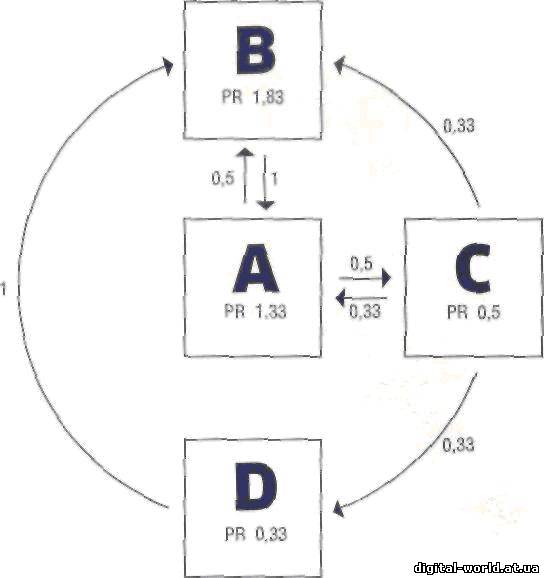
Теперь
представим себе следующую, более сложную ситуацию: страница А имеет
ссылки на В и С; В — только на А; С указывает на А, В и D; D — только
на В. Тогда формула для А будет выглядеть так: PR(A) = 1/1 + 1/3
Ссылка, размещенная на странице В, дает 1, от С мы получаем только
0,33, поскольку она имеет сразу три ссылки. В результате получатся
1,33. Формула для В будет иметь следующий вид: PR (В) =1/2+1/3+1/1
После округления получаем 1,83. Значение для С рассчитывается
так: PR (С) =1/2
То есть 0,5. В конце концов, D имеет: PR(D)=l/3
Или в округленном виде 0,33. В сумме мы вновь получаем общее число всех
страниц: 1,33+1,83 + 0,5 + 0,33 = 3,99 Оно меньше исходного значения на
0,01 из-за округления. В этом вычислении не хватает еще кое-чего: в
результат не включен PageRank каждой страницы. Возьмем еще раз пример с
веб-страницей В. Если ввести в него показатели PageRank, полученные во
время выполнения шага 1, то вместо формулы PR (В) = 1/2 + 1/3 + 1/1
получается:
PR (В) = 1,33/2 + 0,5/3 + 0,33/1 Округленный
результат равен 1,62. Конечно, новое вычисление значения PageRank
для В изменит рейтинги PageRank для страниц А, С и D. А новое
значение D, в свою очередь, изменит
значение В. Поэтому Google приближается к PageRank итеративно, то есть
ступенчато: поисковая система применяет результаты предыдущего прохода
для вычисления следующего шага итерации. По данным Пейджа и Брина,
достаточно 100 итерационных проходов, чтобы получить PageRank мил-
лиардов сохраненных страниц.
Коэффициент затухания: с учетом пользователя
Согласно теории Google, PageRank выражает вероятность, с которой
интернет-пользователь после перехода по случайной ссылке может попасть
на нужную страницу. Но поскольку следует исходить из того, что
пользователь
! делает конечное число переходов, в
формулу был введен коэффициент
i затухания. Он симулирует ситуацию, в которой пользователю надоедает
ходить по ссылкам. Это затухание вычисляется с учетом голосов на
каждую ссылку страницы.
В описании своего алгоритма еще на заре становления Google Сергей Брин и Ларри Пейдж использовали
коэффициент затухания 0,85. Можно, предположить, что коэффициент при сегодняшних расчетах Google близок к
этому значению.
В программах, предназначенных для расчета PageRank, можно увидеть
значения от 0 до 10. Но это всего лишь индекс, настоящее значение
пара-
метра PageRank высчитывается по-другому. Доподлинно неизвестно, какими числами оперирует система,
но есть мнение, что значения для страниц имеют число в пределах единицы
— то есть от 0 до 1. Получаются маленькие десятичные дроби, отражающие
PageRank веб-страниц. Кстати сказать, эксперты пришли еще к одному
любопытному наблюдению: чем выше значение PageRank, тем сложнее его
улучшить. Google использует логарифмическую шкалу, поэтому преодолеть
рубеж PageRank между 2 и 3 гораздо легче, чем между 9 и максимальной
отметкой 10. Стоит отметить, что для подавляющего большинства сайтов
значения PageRank ограничиваются цифрой 5, далее продвигаются только
тысячи сайтов, а значения 10 удостоены единицы.
Фильтры: PageRank
и его маленькие помощники
Используя свою формулу PageRank, Google индексировала Сеть с огромным
успехом. Но триумф вызвал появление паразитов: владельцы веб-сайтов
быстро поняли принцип работы механизма и стали искусственно продвигать
свои страницы. Это привело к тому, что Google начала изобретать новые
методы для защиты от таких хитрецов, a PageRank со временем превратился
лишь в один из факторов, влияющих на положение вебстраниц в результатах
поиска Google.
Тем не менее PageRank часто используют как своего
рода валюту: «Если ты дашь мне две ссылки со страниц с PageRank 4, я
дам тебе одну ссылку со страницы с PageRank 5». Все это довольно
наивно: простой обмен ссылками ничего не дает, тем более если сайты не
связаны одной тематикой.
Однако PageRank — лишь вершина айсберга.
В системе есть десятки фильтров, а также различные методы оценки сайтов
и результатов поиска.
SE0: поисковая оптимизация
Девиз поисковой оптимизации гласит: «Давай хороший код и хорошее,
желательно уникальное, содержание». Тот, кто запомнит это правило,
имеет реальные шансы попасть со своим сайтом на верхние места списков.
Под «хорошим кодом» подразумеваются два свойства HTML-кода
веб-страницы. Во-первых, он должен быть качественным в отношении
синтаксиса, во-вторых, в нем следует употреблять определенные
HTML-элементы. Важными для Google являются прежде всего теги
<title>, <p>,<strong>, а также теги заголовков
<hl>...<h6>. В <title> содержится краткое описание
документа. Этот тег необходимо заполнить правильно, разместив в нем
только важную информацию. С помощью <р> форматируются абзацы,
<strong> позволяет выделить текст жирным, а внутри тегов
<hl>...<h6> следует писать заголовки, причем лучше, если
они будут повторять ключевые слова, по которым продвигается сайт. Важно
использовать заголовок <hl> только один раз, а остальные,
например, <h2> или <hЗ>, чаще.
Еще одной важной
предпосылкой оптимизации результатов поиска является терпение.
Владельцы некоторых сайтов с умом размещают ссылки, постепенно повышая
PageRank, а вместе с тем и популярность страниц.
Тюнинг: Link building
Терпение дано не каждому. Но есть еще одно полезное средство —
оставлять ссылки на свою страницу в блогах и на форумах. Однако ссылки
в комментариях блогов, как правило, автоматически сопровождаются
параметром rel=«nofollow». Это означает, что Google не следует по этой
ссылке и не считает ее голосом при вычислении PageRank.
В
появлении такого правила виноваты спамеры, которые используют
бот-программы, заполняющие блоги и форумы бессмысленными текстами и
многочисленными ссылками.
Link tracking: голосование с помощью кликов
Поисковый гигант Google не стал бы гигантом, если бы не занимался
оценкой поведения пользователей. Анализируя щелчки по ссылкам, можно
выявить популярные результаты поиска.
Но количество кликов вряд
ли внесет изменения в ранжирование сайтов, однако и такую возможность
нельзя исключать. При этом следует помнить, что единственный
действенный способ получить большое число кликов состоит в том, чтобы
дать своему ресурсу хорошее название и описание.
Google выбирает
в качестве заголовка содержимое тега <title>. А для краткого
описания сайта, который отображается под ссылкой, следует использовать
HTML-метатег, где вводится краткое описание документа. Оно может
содержать всю важнейшую информацию страницы и привлечь читателя. <meta name-"description" content-СHIP — лучший журнал о компьютерах"/>
Если у страницы нет такой «выжимки», Google выбирает фрагмент текста и использует его в качестве описания.
Black Hat SEO: как обмануть Google
У каждой системы или программы есть слабые места — даже у Google. С тех
пор как поисковые системы стали предлагать пользователям веб-сайты,
«черные овцы» пытаются всеми способами повлиять на результаты поиска.
Это стало причиной долгой борьбы между спамерами и вла-дельцами
поисковиков. «Черные овцы», так называемые Black Hat SEO,
используют упомянутые лазейки в своих целях. Основные методы спамеров —
это Content Spam и Link Spam. Оба варианта привлекают пользователя на
сайт, который занимает в рейтинге Google очень высокое место. Поскольку
на таких ресурсах рекламные объявления представляют собой единственный
осмысленный элемент содержания, посетитель кликает по ссылке — и
приносит спамерам деньги.
Существует несколько разновидностей
Content Spam. Самый простой способ — заполнить текст повторяющимися
ключевыми словами. Правда, этот метод, называемый Keyword Stuffing, уже
не оказывает такого действия, как прежде, когда поисковые системы
просто подсчитывали частоту появления тех или иных ключевых слов. С тех
пор Google и другие компании приняли против него серьезные меры (www.
google.com/support/webmas ters/bin/answer.py?answer=66358),
«Противоядие» заключается в соотнесении числа ключевых слов в тексте с
его общим объемом (Keyword Density). Начиная с определенного процента
текст может быть расценен как спам.
Еще одна попытка обмана, с
которой Google тоже пришлось столкнуться, — это скрытый текст. Спамеры
пишут белый текст на белом фоне — читатель ничего не заподозрит, но
поисковой системе подсовывают сотни или даже тысячи ключевых слов.
Скрытый текст уже распознается поисковиками.
Часто встречается
Scraping («снятие сливок»), при котором используют содержание чужих
сайтов, чтобы обозначить свое присутствие в Интернете. Спамеры
применяют этот метод в отношении службы Google Adsense, чтобы
заработать деньги с помощью объявле-ний. Scraping вредит прежде всего
сайтам, которые содержат оригинальные тексты. При определенных
обстоятельствах Scrape-страница может получить более высокий рейтинг,
чем оригинальный сайт. Но и с этой бедой антиспамо-вая команда Google
научилась бороться.
|

 Просмотров: 1643
Просмотров: 1643  Дата: 11.01.2026
Дата: 11.01.2026
 Рейтинг: 0.0/0
Рейтинг: 0.0/0





